ETLとELTの違いとは?それぞれの特徴・機能・性能から選び方を解説
最終更新日:2023/07/28
目次
この記事では、ETLとELTの違いから始まり、データフローの基本的な概要や特徴、性能差を詳しく解説します。データの抽出・変換・ロードのプロセスに焦点を当て、それぞれの手法の利点や選択基準、ベストプラクティスを探ります。また、データフローの未来展望にも触れ、AIとの連携やクラウドの活用がデータ処理の進化を予測します。データエンジニアの役割も変化する中、効率的なデータフローの構築に向けた戦略を考察します。
ETLとELTとは何か?
ETLとELTの基本的な定義
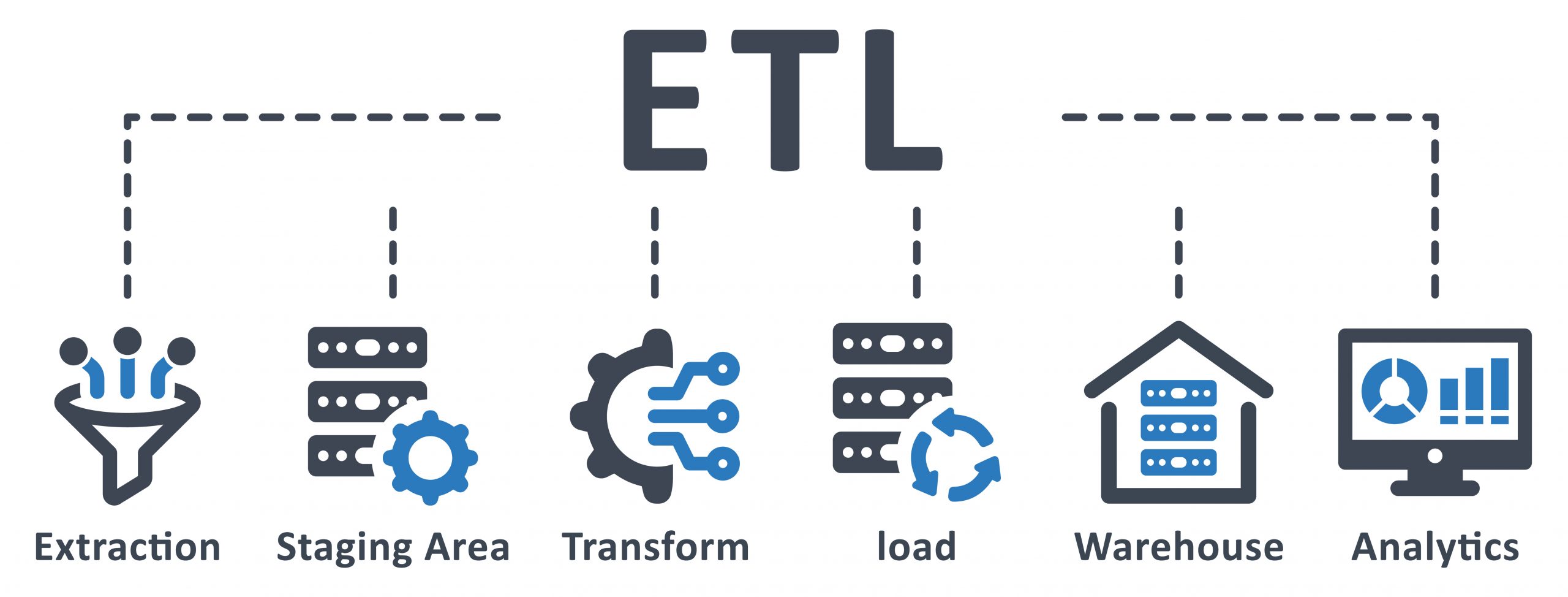
ETL(Extract, Transform, Load)とは、データを取得し(Extract)、必要な形式に変換し(Transform)、別のデータストレージにロードする(Load)プロセスです。一方、ELT(Extract, Load, Transform)は、データを取得し(Extract)、まず別のデータストレージにロードし(Load)、その後必要に応じて変換するプロセスです。ETLは変換処理を行うため、データウェアハウスなどの前処理に適している一方、ELTはクラウドストレージのような柔軟な環境で活躍します。
ETLとELTの違いとは?
ETLとELTの主な違いは、データの変換処理のタイミングです。ETLではデータを取得後に変換し、その後ロードしますが、ELTではデータを取得してからロードし、必要な時点で変換を行います。これにより、ELTは新たな変換ニーズに柔軟に対応できます。ただし、変換処理がロード後に行われるため、データが大量になる場合には処理時間に注意が必要です。
データフローの概要
データフローはETL/ELTの中心的なコンセプトです。データフローとは、データが抽出され、変換され、ロードされる一連のプロセスの流れを指します。ETLではデータが抽出された後、変換処理によってクレンジングやデータ型の変更が行われ、最終的にターゲットデータベースにロードされます。一方、ELTでは抽出された生のデータがまずロードされ、その後必要なタイミングで変換処理が実行されます。
ETLの特徴と機能
データ抽出(Extract)の仕組み
ETLのデータ抽出は、さまざまなデータソースから情報を取得する重要なステップです。データベース、クラウドストレージ、API、ログファイルなどのソースからデータを効率的かつ安全に抽出するため、APIキーの使用やクエリの最適化などの方法が用いられます。また、抽出されたデータはデータの整合性を保つためにトランザクション的に処理されます。
データ変換(Transform)の重要性
データ変換はETLの中でも特に重要なフェーズです。不要なデータのフィルタリング、データ型の変換、欠損値の処理、データの集計などが行われます。さらに、異なるデータソースから取得したデータを統一された形式に変換し、データ品質を確保します。この段階での注意深い処理が、後段のデータロードや分析の信頼性を高める鍵となります。
データロード(Load)の手法と注意点
データロードは、変換されたデータをターゲットデータベースやデータウェアハウスに保存するプロセスです。バッチ処理やストリーミング処理を活用してデータのロードを行います。特に大量のデータを扱う場合は、パフォーマンスを最適化するため、適切なインデックスの設計や分散処理の導入が必要です。さらに、エラー処理やトランザクションの管理にも十分な配慮が必要です。
ETLの利点と欠点
ETLの利点は、データの事前加工によるデータ品質の向上や、複数のデータソースからのデータ統合が容易になることです。また、データの保守性や可読性が向上することで、データの信頼性が高まります。一方で、ETLはデータ変換による処理に時間がかかることや、データの更新に適さないことが欠点として挙げられます。
ELTの特徴と機能
データロード(Load)とは何か?
ELTでは、データを取得(Extract)した後、まずターゲットデータベースやデータウェアハウスにロード(Load)します。この段階では、データを生の形式で保存するため、データの移送にかかる時間を最小限に抑えることが可能です。データロードが終了した後、データの変換処理が実行されるため、柔軟な分析やクエリが可能になります。
データ変換(Transform)のタイミングと方法
ELTではデータ変換はロード後に行われます。このアプローチにより、データがターゲットデータベースに保存された後、変換処理が実行されるため、ビッグデータやリアルタイムデータへの対応が容易です。データ変換はSQLクエリを使用したデータ加工や、ビッグデータプロセッシングフレームワークを利用した分散処理が一般的です。
ELTの利点と注意すべき点
ELTの利点は、データの柔軟性と拡張性にあります。データが生の形式で保存されるため、新たな変換ニーズに対応するのが容易です。また、分散処理の導入により、大規模データにも対応できます。ただし、データロード時には生のデータが保存されるため、データ品質の保証やセキュリティ対策が重要となります。
ETLとELTの性能差
データ量と処理速度の比較
ETLとELTの性能差はデータ量や処理速度によって異なります。ETLではデータの変換処理がロード前に行われるため、大量データの場合、処理に時間がかかる可能性があります。一方、ELTはデータロード後に変換処理が行われるため、ビッグデータの処理に適しています。
エラー処理と信頼性の違い
ETLとELTではエラー処理と信頼性の観点で異なるアプローチを取ります。ETLでは、データの変換がロード前に行われるため、変換処理のエラーがロードに影響を及ぼす可能性があります。一方、ELTではデータロードが先に行われるため、変換処理のエラーは影響を最小限に抑えることができます。
拡張性と柔軟性の観点から見た違い
ETLとELTの拡張性と柔軟性は、データの変換タイミングによって異なります。ETLは変換処理をロード前に行うため、変換処理に対する変更が発生する場合、全体のプロセスを再設計する必要があるかもしれません。一方、ELTはデータロード後に変換処理が行われるため、新たな変換ニーズに柔軟に対応できるという特徴があります。
ETLとELTの選択基準
データソースとシステム要件の分析
ETLとELTの選択にあたっては、まずデータソースとシステム要件を十分に分析することが重要です。データの取得元やデータ量、処理頻度などを把握し、どちらの手法が最適かを判断します。データソースが多岐にわたり、データ量が大きい場合はELTの柔軟性を活用することが適しているかもしれません。
データ品質とセキュリティの重要性
ETLとELTの選択において、データ品質とセキュリティを重要視することが不可欠です。ETLでは変換処理が前段で行われるため、データ品質の保証がより厳密になります。一方、ELTはデータを生のままロードするため、データのセキュリティ対策に十分な注意が必要です。データの機密性を損なわず、安全な処理を行うことが重要です。
予算と運用コストの比較
ETLとELTの選択には、予算と運用コストの比較も欠かせません。ETLはデータの前処理が複雑なため、導入コストが高くなることがありますが、一方でデータロード後の処理は比較的効率的です。一方、ELTはデータロード時のコストが低い一方で、データの変換処理に要するコストが増加する可能性があります。組織の予算と運用リソースに合った手法を選択することが重要です。
ビジネスニーズへの適合性を判断するポイント
ETLとELTの選択においては、最終的なビジネスニーズへの適合性を判断することが重要です。データの分析、レポート作成、ビッグデータ処理、リアルタイム分析など、ビジネス上の要件によって最適な手法が異なります。ビジネスニーズを具体的に把握し、それに応じたETLまたはELTの利用を検討してください。
ETL/ELTのベストプラクティス
データの可視化とモニタリング手法
ETL/ELTプロセスの可視化とモニタリングは、データの品質と信頼性を確保するために重要です。ジョブの実行状況やエラーログをリアルタイムで可視化し、問題発生時に素早く対応できる仕組みを構築しましょう。また、データ品質の監視やデータのヒストリカルトレースにより、データの信頼性を向上させます。
オーケストレーションと自動化の重要性
ETL/ELTプロセスのオーケストレーションと自動化は、効率的なデータ処理を実現するために必要です。ワークフローの自動化により、複雑なデータパイプラインを容易に管理できます。タスクの依存関係やスケジュールを設定し、人的ミスを減らすことで、データの正確性を高めます。
データ品質向上のための戦略
ETL/ELTプロセスにおいては、データ品質の向上に重点を置くことが必要です。データ品質の評価基準を設定し、不正確なデータの除外や欠損値の補完を行う方法を検討します。データ品質の向上により、正確な分析結果を得ることができ、組織全体の意思決定に寄与します。
成功事例と学ぶべき失敗例
ETL/ELTの導入にあたっては、他社の成功事例と失敗例を学ぶことが重要です。成功事例からは、効率的なデータ処理や最適なアーキテクチャを学び、自社の導入に生かすことができます。一方、失敗例からは、問題点や課題を把握し、同じ失敗を避けるための教訓を得ることができます。他社の事例を参考にしながら、自社の状況に適したETL/ELTのベストプラクティスを見つけることが重要です。
データフローの未来展望
バッチ処理とストリーミング処理の融合
データフローの未来展望では、バッチ処理とストリーミング処理を融合させることが注目されています。これにより、大量データのバッチ処理とリアルタイムデータのストリーミング処理を組み合わせ、より迅速なデータ分析と洞察を可能にします。データフローの効率性と柔軟性が向上し、ビジネス上の意思決定により迅速に対応できるでしょう。
AIとの連携による自己最適化の可能性
データフローの未来では、AIとの連携により自己最適化が進むと期待されています。AIがデータフローのパフォーマンスやエラーの予測、最適化を行い、効率的なデータ処理を実現します。自動チューニングや自己学習により、データフローがよりスマートに運用され、データエンジニアの負担が軽減されるでしょう。
クラウドとの相性とそのメリット
データフローの未来において、クラウドとの相性がますます重要になります。クラウド上でのデータフローはスケーラビリティが高く、柔軟なリソースの利用が可能です。また、クラウドサービスの進化により、セキュリティや可用性の向上が期待されます。クラウドを活用することで、より効率的でコスト効果の高いデータフローが実現します。
データエンジニアの役割とスキルセットの変化
データフローの未来において、データエンジニアの役割とスキルセットに変化が見込まれます。データフローの自動化やAIとの連携により、単純なルーチン作業は自動化される一方で、戦略的なデータ分析やデータマネジメント能力が求められるでしょう。データエンジニアはビジネスに対して価値を提供するデータストラテジストとしての役割が拡大すると予想されます。
まとめ
この記事では、ETLとELTの違いから、それぞれの特徴と機能、性能差を解説しました。データフローの基本的な概要から、選択基準やベストプラクティスまで、詳細にお伝えしました。ETLは前処理に適している一方、ELTは柔軟なデータ処理が可能です。データ変換のタイミングやデータロードの手法など、違いを理解することで、ビジネス上のニーズに応える適切な選択が可能です。未来展望では、AIとの連携やクラウドの活用がデータフローの進化を見据えています。データエンジニアの役割も変化する中、最適な戦略を構築することが求められます。ビジネス環境に応じて、ETLとELTの利点を生かし、データフローを最適化しましょう。
おすすめ比較一覧から、
最適な製品をみつける
カテゴリーから、IT製品の比較検索ができます。
1795件の製品から、ソフトウェア・ビジネスツール・クラウドサービス・SaaSなどをご紹介します。
(無料) 掲載希望のお問い合わせ